
書籍の編集作業のひとつに、表記統一があります。 表記揺れとは、「行う」と「おこなう」のように、意味は同じなのに表記が違うものが文章のなかに混在している状態です。表記揺れがないように全体に表記を整える作業が表記統一です。
簡単な例だと、次のようなものがあります。
くみあわせ/組み合わせ/組合せ(漢字・送り仮名) コンピュータ/コンピューター(音引きの有無) ねこ/猫/ネコ(ひらがな・漢字・カナなどの表記) 1ヶ月/1か月/1カ月/1ヵ月 0/0(全角・半角) 1000/1,000(桁区切りの有無) WWW/ワールド・ワイド・ウェブ/ウェブ(固有名詞の表記・略記など) アプリ/アプリケーション(略称にするか) 我々/私たち(呼称)
小説などの読み物では、意図的に表記を変えている場合もあるでしょう。そもそも意味が正しければ揺れていても気にならない、という方もいるかもしれません。しかし、内容に集中するためには表記揺れはないほうが読みやすい文章になります。たとえば「こっちではリポジトリと書いてあったのに、あっちではレポジトリと書かれていた」といった微妙な違いがあると、読み手が用語の違いに気を取られ、思考を妨げられてしまう可能性があります。
さて、表記統一を行う際に便利なのが、検索・置換です。 目視によるチェックには、チェック漏れが発生します。そもそも数百ページの書籍全体を目で眺めてチェックするのはかなりの手間になります(斜め読みで1ページ30秒で判断したとしても、50分以上かかりますね)。 そのため、機械的な検索・置換を利用することになります。
上の例で言えば、希少/稀少のような単純な文字列であれば普通に検索するだけで問題なくチェックできます。 しかし、単純な文字列検索では「行う/おこなう」のように活用がある場合は簡単に検索できません。 そこで利用するのが正規表現です。
正規表現とは
正規表現とは、「文字列の集合を1つの文字列で表現する方法の1つ」(Wikipedia)です。数学やコンピュータサイエンスの分野から発展したものですが、興味のある方は歴史や理論的背景も見てみてください。
多くのプログラミング言語ではライブラリによって正規表現をサポートしています。また、多くのテキストエディターで正規表現による検索・置換が利用できます。なお、ワードの「高度な検索と置換」は正規表現検索・置換ではありません。
では、実際に編集するときにも使える正規表現による検索の例を見てみましょう。使用している文法については適宜解説します。
正規表現の例1:数の桁区切りが入っているか調べたい
「1,000」のように数に桁区切りの「,」を入れる場合がありますが、この有無が揺れている場合があります。桁区切りを含まない4桁の数を検索する場合、次のようになります。
\d{4}
\dは半角数字(0〜9)にマッチします。これはPerlの拡張正規表現のひとつであり、多くのプログラミング言語やソフトウェアで取り入れられています。\dは[0-9]と等価です。[0-9]は[]の中の文字のうち1文字にマッチすることを表します。-はここでは範囲を表し、0〜9の文字を表すことになります。
{4}は、直前の表現(ここでは\d)が4個あることを示します。もちろん4個並べて書いても同じ意味になります(ここでは\d\d\d\d)。繰り返しの数を範囲で指定したい場合は、{3,6}(3〜6個)、{3,}(3個以上)といった形で記述します。
以下の正規表現はいずれも同じ意味になり、すべて4桁の数を表します。
\d{4}
[0-9]{4}
[0-9][0-9][0-9][0-9]
\d\d\d\d
桁区切りを含む4桁の数であれば、次のようになります。0〜9のうち1文字に続いて,があり、さらに0〜9の数字が3つ並ぶ、という形ですね。
\d,\d{3}
西暦の場合を除外
さて、この桁区切り、通常、西暦を表現するときには挿入しません。そこで、2024年のようなパターンを除外すると、
\d{4}[^年]
となります。[^年]は『「年」以外の1文字』を表します。これで、「1000m」にはマッチするけど「2024年」にはマッチしない、という正規表現になります。なお、[^]は[]の否定であり、括弧内に範囲を指定したり列挙したりすることも可能です。
メタ文字について
この例に出てきた\や[、]のように、その文字列そのものではなく特殊な意味を持つ文字のことをメタ文字と言います。正規表現におけるメタ文字としては、* + ? $ ^ . () | \ {} []があります。\は後続の文字によって文字集合を表したり、メタ文字のエスケープにも用いられたりします。
正規表現の例2:「行(な)う」を見つけたい
活用を含めた「行う」にマッチする正規表現は次のようになります。
行な?[わいうえおっ]
?は、直前の表現が0個か1個あることを示します。この例では「な」の有無の揺れを吸収しています。「行う」ではなく「行なう」と書く人もいるので、このような例にしてみました。
[わいうえおっ]の部分は、前述の通り、[]の中に列挙されている文字のうち1文字にマッチします。「行う」「行わ(ない)」など、活用も加味した表現になっています。
これで検索すると「行なう」「行い」などにマッチすることになります。
正規表現の例3:誤った桁区切りを見つけたい/ChatGPTの活用
さきほどの「例1」で見た桁区切りのパターン、「10,00」のような誤った桁区切りの場合は考慮しておらず、検索することができません。誤った桁区切りを探す場合、次のような正規表現が考えられます。
\d{4,}|\d{1,3}(,\d{3})*,\d{1,2}(?!\d)|\d{1,3}(,\d{3})*,\d{4,}(?!\d)
1000(桁区切りがない)、10,00,000(2番目のカンマのあとが2桁)、1,2345(カンマのあとが4桁)、1,23,456(途中のカンマのあとが2桁)、10,000,00(最後の部分が2桁)、123,45,678(2番目のカンマのあとが2桁)といったものにマッチして、桁区切りが正しいもの(1,000、12,345、1,234,567、123,456,789など)にはマッチしません。
考慮すべきパターンが多かったので、ChatGPTと対話しながら作ってもらいました。各部分を解説すると次のようになります。
\d{4,}:4桁以上の数字にマッチ。- または(
|) \d{1,3}:1~3桁の数字にマッチ(千の位未満の部分)。(,\d{3})*:カンマのあとに3桁の数字が0回以上繰り返されるパターンにマッチ(「正しい」カンマ区切り)。,:次に来るカンマ。\d{1,2}:カンマの後に1~2桁の数字が続く場合(これが不正なパターン)。(?!\d):数字の後に別の数字が続かないことを確認(否定先読み)。- または(
|) \d{1,3}(,\d{3})*,\d{4,}:同様に、途中まで正しいカンマ区切りが続いたあとに、4桁以上の数字がカンマの後に続く場合にマッチ(これも不正なパターン)。
複雑な印象を受けると思いますが、正規表現の知識があまりない状態でもこういった例を作ることができます。逆に、何か正規表現を見つけたとき、ChatGPTに渡して「解説して!」と頼むと、記法の解説やマッチする例を教えてくれて便利です。作成するときも、理解するときも、ChatGPTをうまく活用してみるとよいでしょう(誤っている場合もあったり、考慮が足りない場合もあるので、実際に使うときは慎重に確認してください。考慮不足をChatGPTに指摘すると適宜直してくれます)。
実際に使ってみると…
この記事を対象に、「例3」の正規表現を検索してみると、次のようになります(ここではCotEditorを用いました。「正規表現」にチェックが入っています)。
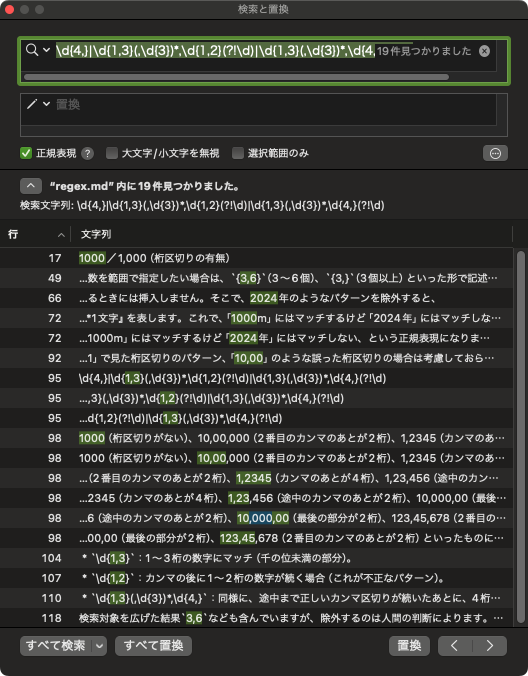
適切な桁区切りのものは排除するようにしたので含まれておらず、対象のものは検索結果に含まれているようです。ただ、検索結果には3,6なども含まれています。これを除外するのは人間の判断によります。 もっと単純な正規表現、たとえば、
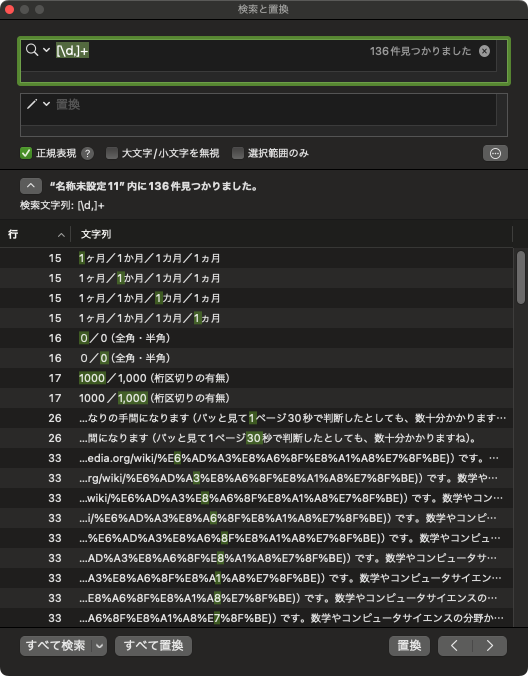
[\d,]+
で数字(0〜9)とカンマ(,)を含むすべての文字列を検索すればよいのでは?と思われるかもしれませんが、これでは修正の必要がないテキストにもマッチしてしまい、大量に該当した場合は直すべきものを探すのが大変になります。実際、同じテキストに対してこの正規表現を検索してみると、次のようになります。1桁の数など、明らかに問題のないものも検索結果に含んでいます。
単純すぎる表現ではマッチしすぎる、複雑すぎる表現では意図しないマッチ漏れが発生するかもしれない、という問題があるので、明らかなものは除外しつつ、数の多くないものは人間側で判断する、という場面も出てくるでしょう。
(もっと機械的に頑張りたい場合はテキストを処理するプログラムを書けばよいのですが、ここでは、シンプルな正規表現検索を用いて、必要な場合は人間側の判断も利用しながら使うことを想定しました。)
おわりに
この記事では、表記統一の必要性について説明し、編集時にも使う簡単な例を3つ紹介して、実際に検索を実行してみました。単純な文字列検索では調べづらい例があることをお分かりいただけたでしょうか。
今回はあえてトップダウンに正規表現を示して説明しましたが、文法の説明については別の記事で紹介する予定です。
R&D M