
“The best way to predict the future is to invent it.”
(未来を予測する最善の方法は、それを発明することだ)
「GUI」や「オブジェクト指向」など、現代のコンピュータの基礎を築いた天才研究者、アラン・ケイの言葉です。
最近の画像生成AI、すごいですよね。コツをつかめば、テキストだけでそれっぽい画像が簡単に量産できてしまう。
美麗なイラストやグラフィックがどんどん出力されてワクワクする一方、目まぐるしくかわる状況にぼんやりとした不安を感じている人もいるかもしれません。
だからこそ、画像生成で何が行われているのか、なんであんなことが可能なのか、今こそちゃんと知りたくありませんか? アラン・ケイのように「未来を発明する」のは難しくても、理屈がわかれば、きっと少しは先にあるものが見えてくると思いませんか?
それに答えてくれるのが、ここで紹介する書籍『Pythonで学ぶ画像生成』(機械学習実践シリーズ、北田俊輔 著、インプレス刊。弊社で編集、組版を担当)です。
最初にお断りしておきますが、本書は「この手順に従えば、ほら、誰でも簡単にすごい画像が生成できますよ!」という本ではありません。ふんわりした比喩でお茶をにごしたりもしません。ガチです。各技術のコアとなる理論を説明し、それをPythonで実践する方法をしっかり紹介した、本気で学びたい人のための画像生成技術入門です。
情報がみっちり詰まった全368ページ
本書の何がすごいか。それは、現在の画像生成技術の前提知識、超重要概念(拡散モデル、潜在空間、CLIPなど)、画像生成界のエースStable Diffusionの仕組みと進化、そしてLoRAやControlNetをはじめとした、画像生成をさらにコントロールするための応用技術にいたるまで、みっちりぎっちり詰まっているところです。
Stable Diffusion v1/v2/XL/v3をすべて解説した第4章もすごい充実度ですが、圧巻なのは応用技術を紹介した第5章。これだけの数の技術について、理論的な解説と実装のポイントが用意されています(そして後述のサンプルも!)。
5-1. パーソナライズされた画像生成
- Textual Inversion
- DreamBooth
5-2. 制御可能な画像生成
- Attend-and-Excite
- ControlNet
5-3. 拡散モデルによる画像編集
- Prompt-to-Prompt
- InstructPix2Pix
- Paint-by-Example
5-4. 画像生成モデルの学習および推論の効率化
- LoRA
- LCM
5-5. 学習済み拡散モデルの効果的な拡張
- GLIGEN
- SDXL-Turbo
5-6. 生成画像の倫理・公平性
- SLD
- TIME
いまやアドホックな知識がほしければ、どれだけでも生成AIを頼れます。もう、専門書、技術書なんてオワコンじゃない?という人もいるかもしれません。しかし、寄せ集めじゃない、エキスパートの手によって取捨選択された包括的な知識が得られるのは書籍ならではのメリットです。
ぶっちゃけ、ネットでこれだけの知識を探してくることを考えたら、絶対さっさと本書を購入して読み込んだほうがコスパいいですってば! そこは間違いない。
制作担当として言わせていただければ、よくぞこの情報量がこのページ数で収まったと思います。もちろん、著者の北田さんの熱意と深い専門知識があってこそ実現した奇跡の一冊です。
すぐに試せるサンプルコード
本書のサンプルコードは、すべて完全な形でGitHubリポジトリで公開されています。さらに、GitHubから各サンプルをそのままGoogle Colabで開くこともできるので、思い立ったらすぐにコードを実行できます(なんて親切!)
本書のサンプルGitHubページ( https://github.com/py-img-gen/python-image-generation )
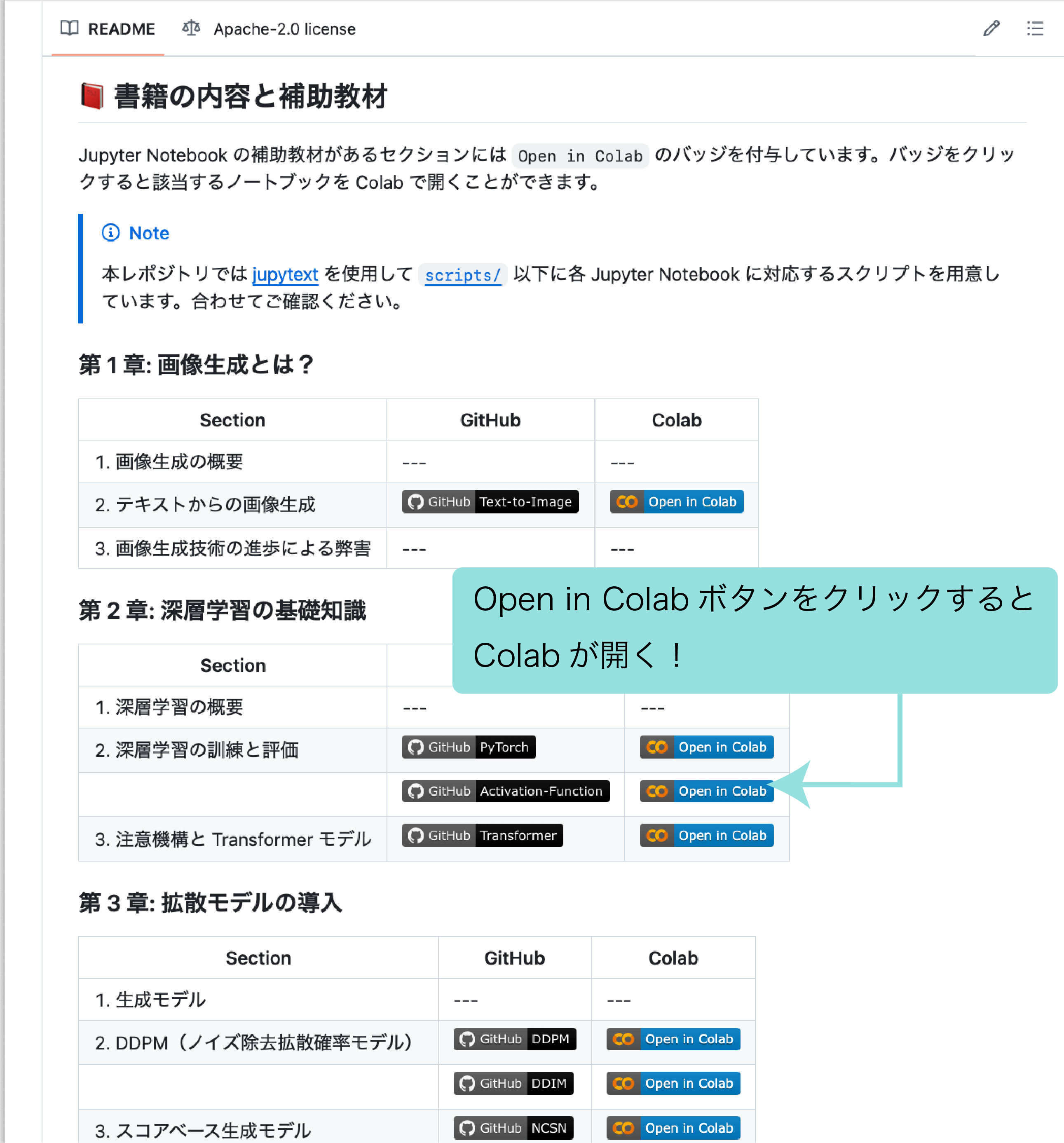
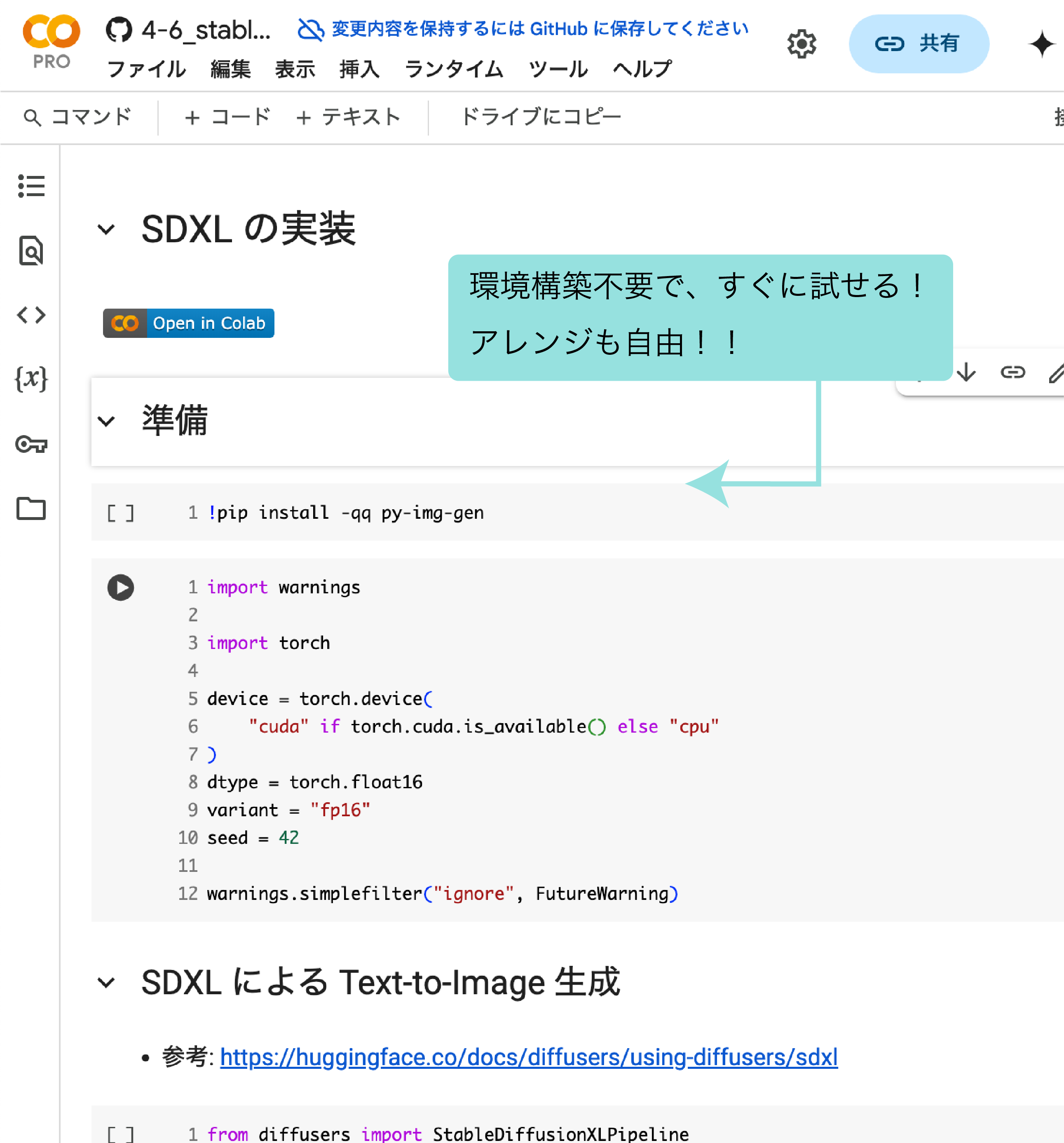
このコードを好きなだけこねくり回し、自分でデータを追加したり、パラメータを変え実行してみることで、説明だけではつかみにくい各部分の意味や動作を体感できるはずです。
Pythonの文法的な知識はある程度、前提となっていますが、きれいに整理されたコードですので、プログラミングの経験が少しでもあれば、コード自体を理解するのはそれほど難しくないと思います。細かい部分については、Google Colabにお住まいのGeminiに聞いてもよいですしね。
未来を発明する第一歩
2025年4月現在、ChatGPT 4oの自己回帰モデルによる画像生成も話題になっていますが、本書が扱う拡散モデルも今後、まだまだ進化を続けていくものと思われます。 本書で学んだ知識は、今後も最先端の技術を理解するための基礎となるはずです。
AIに振り回されるのではなく、AIを利用して、乗りこなしていく側に立ちたい。
そう思うのであれば、ぜひ本書と向かい合って、画像生成の世界へ飛び込んでほしいなと思います。
おまけ:LoRAを試してみた
せっかくなので、本書のサンプルで実際にLoRAを試してみました(このために、Google Colab有料版チャージしました!)。
LoRAは、もとの画像生成モデル全体はいじらずに、比較的少ない計算コストで画風やキャラクターの特徴などをモデルに反映させるファインチューニング技術です。
本書で学習に使用しているのはJustin Pinkeyさんが公開している浮世絵の中の人物の顔を集めたデータセット https://www.justinpinkney.com/blog/2020/ukiyoe-dataset/ 。これに著者 北田さんがBLIP2で英語キャプションを付与したものです(https://huggingface.co/datasets/py-img-gen/ukiyo-e-face-blip2-captions )。
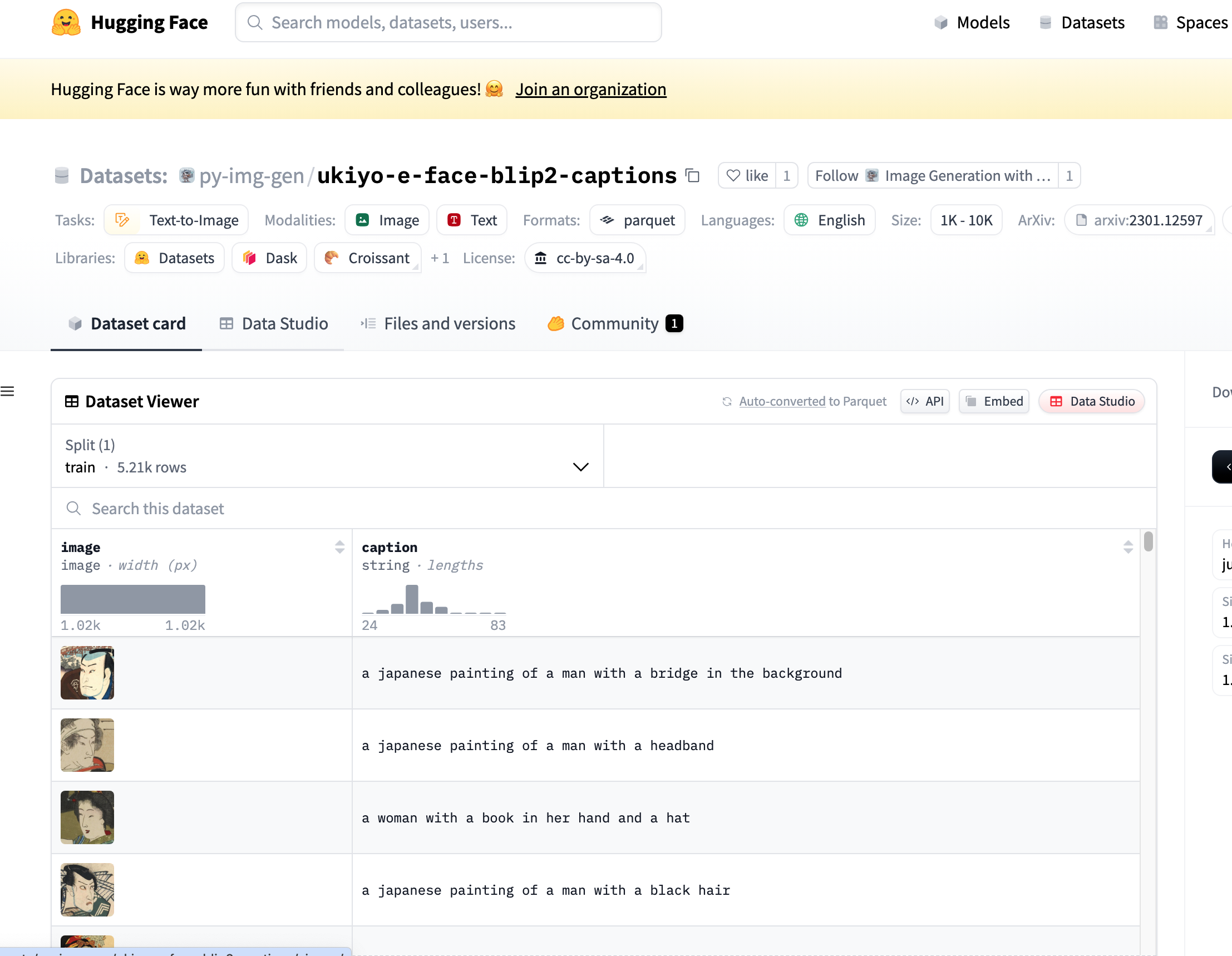
最初うっかりT4 GPU(比較的遅いやつ)でサンプルのまま実行したところ数時間たっても終わる気配がなかったので、ランタイムをA100 GPU(とっても速いやつ)にして、なおかつエポック数を100→10にして実行したところ、実行時間41分。 学習が終わりました。
さっそく出力してみましょう。まずは、サンプルでのデフォルト、モナリザさんです。
Prompt「Mona Lisa」

雰囲気はわかります、雰囲気は。
次、白雪姫。
Prompt「Snow White」

どちらかといえば継母っぽいですね。
次、エルビス・プレスリー。
Prompt「Elvis Presley」

浮世絵というよりは、19世紀のイギリスの小説の挿絵です、とか言われたほうが納得しそうです。
それにしても、Promptでは人物名しか言及していないのに、構図はほぼ同じ、画風も(浮世絵の範疇には収まりきってない気もしますが)学習データに強い影響をうけていることがわかります。
途中で動物がいい感じに出力されることに気づきました。ヤギ、うさぎ、カピバラ。
Prompt「goat」

Prompt「rabbit」

Prompt「capybara」

カピバラ、かわいい。
顔のアップにはなり得ないプロンプトだとどうなるのでしょうか。本書でも何回も登場する「馬に乗った宇宙飛行士」
Prompt「An astronaut riding a horse」

やはり無理があったようです。構図を変えざるを得ないものは厳しいということか。これはこれで、シュールな魅力を感じるイラストですが。
「バラ」
Prompt「roses」

どうしてもそっちに寄せていきたい強いお気持ちを感じます。
データセットとかけ離れたものも試してみました。「祭り」です。
Prompt「A festival」

ここまで違うと、線や色味の雰囲気だけを抽出した感じになるんですね。異国情緒漂う不思議な絵ですが、どこか懐かしみを感じるのは浮世絵のDNAを引き継いでいるからでしょうか?
日和ってエポック数を10まで絞ってしまいましたが、サンプル数が多いせいか、意外に学習成果が画像に反映されているようです。次はパラメータを変えて、どれくらい変化があるのか試してみたいところです。
みなさんも、本書片手に、ぜひいろいろ実験してみてください。
(R&D かつの)